AI data preparation services
Ngày: 22/03/2025
Basically, the steps to solve a Deep Learning problem in Computer Vision include:
1. Collect data for the problem.
2. Label the collected data.
3. Select Deep Learning models suitable for the problem, conduct training, testing and evaluation.
4. Repeat the above steps until the requirements of the problem are satisfied.
Most of us are interested in step 3 of the problem, which is the step of selecting models and methods to improve model hyperparameters to achieve the lowest error rate, giving the most accurate results.
The first two steps seem quite simple but are extremely important and we often ignore them.
- Step of collecting data to train the model: Deep Learning models cannot operate without data, if the data set is too small, it is easy to overfit and the model cannot learn all the features for the overview cases.
- Data labeling will evaluate whether our model works well or not. Wrongly labeling data will make the model predict and evaluate wrongly, wasting a lot of time and effort on the training process.
So how to find "enough" training data and label it? How to label the data? And who will label the data? It can be said that this is the most time-consuming and labor-intensive process of Deep Learning in Computer Vision.
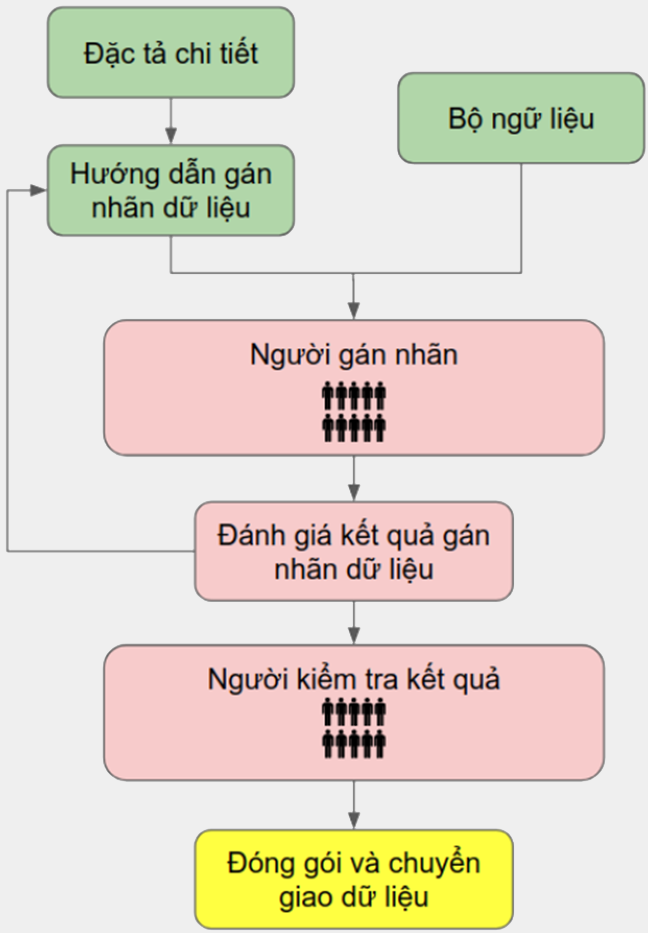
Data Labeling Process
AVA provides AI data preparation services that help customers quickly and accurately solve the problem of data collection and labeling.
